LoRA(Low-Rank Adaptation)はAIの追加学習ツールで、自分の好みの画像を学習データとしてAIを再学習させることができます。自分で作成した『Lora』を使用することで、特定のイラストのスタイル調整や、特定の人物やキャラクターで画像を生成することができるようになります。
好きな人物の画像を生成することも可能ですが、著作権や肖像権の問題には十分注意が必要です。
有名人やキャラクターの画像を学習させる場合は、公開せず、私的利用に限定してください。
LoRAに限らず、生成した画像全般についても同じ注意が必要です。
『Lora』モデルの特長
LoRAモデルとは、AIが生成する画像をより詳細かつ特定のスタイルに合わせて改良するための技術です。この「低ランク適応(LoRA)」技術は、AI画像生成モデルを素早く、そして効果的に調整することを可能にします。この調整により、AIは特定のキャラクターやアートスタイル、あるいは特定のテーマに基づいた画像をより正確に作成できるようになります。
たとえば、ある特定の漫画のキャラクターや有名な画家の画風を模倣したい場合、LoRAモデルを使用することで、AIはその特定のスタイルや特徴を捉えた画像を生成することができます。LoRA技術は、AIが一から学習するのではなく、既存のモデルを特定の方向に「微調整」することに重点を置いています。これにより、時間とリソースを節約しつつ、多様なビジュアルスタイルやテーマに対応するカスタマイズされた画像生成が可能になります。
簡単に言えば、LoRAモデルはAIに「特定のスタイルの言語」を教えるようなものです。これにより、AIはその言語を理解し、そのスタイルやテーマに応じた画像を作り出すことができるのです。
Loraモデルの種類
LoRAモデルは、AI画像生成において特定のニーズに対応するために開発された複数のモデルがあります。ここではそれぞれの種類をより具体的に分かりやすく解説します。
-
キャラクターLoRA: このモデルは特定のキャラクターを生成するために使用されます。例えば、漫画やアニメ、ビデオゲームの特定のキャラクターのスタイルを模倣し、そのキャラクターに似た画像を生成するのに適しています。
-
スタイルLoRA: このモデルは特定の芸術家のスタイルや一般的な芸術的なスタイルを模倣するために使用されます。例えば、印象派の画家のスタイルを再現するために使用されることがあります。
-
コンセプトLoRA: 特定の概念やアイデアに焦点を当てた画像を生成します。たとえば、「未来都市」や「和風の風景」といった特定のテーマに基づいて画像を生成する場合に役立ちます。
-
ポーズLoRA: このモデルはキャラクターを特定のポーズで生成するために使用されます。例えば、特定の動きやアクションをしているキャラクターを描くのに適しています。
-
服装LoRA: キャラクターの服装やアクセサリーを特定のスタイルで生成するために使用されます。これにより、キャラクターにさまざまなファッションやアクセサリーを着せることができます。
-
オブジェクトLoRA: 物体やアイテムを生成するために特化したモデルです。家具、植物、車など、特定のオブジェクトのスタイルに焦点を当てた画像生成が可能です。
これらのLoRAモデルは、AIを用いて特定の視覚的要素やスタイルに特化した画像を生成することを可能にします。それぞれのモデルは特定のタイプの画像生成に特化しており、アーティストやデザイナーが独自の創造的なビジョンを実現するのに役立ちます。
Loraモデルの使用方法
LoRAモデルを利用する方法は、以下のステップで分かりやすく説明できます。これにより、AIを使った画像生成において、特定のスタイルやテーマに合わせたカスタマイズが可能になります。
-
LoRAモデルのダウンロード:
- まずは、インターネット上のオープンソースリポジトリから、希望するLoRAモデルをダウンロードします。これらのモデルは無料で公開されており、様々なスタイルやテーマに特化したものが用意されています。具体的には、civitaiのHPでダウンロードできます。
-
LoRAモデルのインストール:
- 次に、ダウンロードしたLoRAモデルを、AI画像生成用のソフトウェアにインストールします。例えば、「Automatic1111」の場合では、models/loraフォルダにLoraファイルを保存することで、LoRAモデルを利用できるようになります。具体的な手順については本記事の後半に記載がありますので参考にどうぞ。
-
LoRAモデルの使用:
- インストールが完了したら、LoRAモデルを使用して、AIアートを生成します。Automatic1111 WebUIのようなインターフェースでは、モデルを選択し、生成したい画像のパラメータを設定します。例えば、特定のキャラクタースタイルやポーズ、スタイルなどを指定することができます。
- その後、AIに画像の生成を開始させます。プロセスが完了すると、指定したスタイルやテーマに合わせたカスタマイズされた画像が生成されます。
このプロセスにより、LoRAモデルを活用して、独自のビジュアルスタイルやテーマを持つAI生成画像を作成することができます。特にアーティストやデザイナーにとって、この技術は創造的な表現の幅を広げる大きな可能性を持っています。
Loraモデルの活用例
LoRAモデルの応用は、AIによる画像生成の分野で広く使われており、さまざまなシナリオでその価値を発揮します。以下に、LoRAモデルがどのように応用されるか、具体的な使用例を挙げて説明します。
-
キャラクターデザインの強化:
- LoRAモデルは、特定のキャラクターやスタイルを持つキャラクターの生成に使用されます。例えば、ゲーム開発者やアニメーションクリエイターが、独自のキャラクターデザインを迅速かつ効果的に作成するために利用できます。
-
アートスタイルの模倣:
- 特定の画家や芸術運動のスタイルを再現するために、LoRAモデルが使用されることがあります。これにより、アーティストはインスピレーションを得たスタイルで新しい作品を創出することができます。
-
テーマに基づく画像生成:
- 特定のテーマやコンセプトに沿った画像を生成する際にもLoRAモデルが役立ちます。例えば、特定の時代背景や文化的要素を含んだ画像を生成することが可能です。
-
カスタマイズされたビジュアルコンテンツの作成:
- LoRAモデルは、ウェブデザイン、広告、マーケティングなどで、特定のブランドイメージやメッセージに合わせたビジュアルコンテンツを作成するのに適しています。
-
教育用ビジュアルエイドの生成:
- 教育分野においても、LoRAモデルは歴史的な場面や科学的な概念を視覚化するために使われます。これにより、教材がより魅力的で理解しやすくなります。
-
個人的な創作活動:
- 趣味でアート作品を作る個人も、LoRAモデルを使用して、独自のアイデアやビジョンに基づいた作品を創出できます。
LoRAモデルの応用は、これらの例に限らず、創造的な活動の幅広い分野で可能性を秘めています。特に、画像生成のカスタマイズ性と精度を高めたい場合に、この技術は大きな助けとなるでしょう。
LoRAの作り方
Loraの作り方ですが、Stable Diffusionの拡張機能である「sd-webui-train-tools」を使って作成します。
これを使うことで、画像調整やタグ付けなど面倒な操作をすることなく、20枚程度の画像をドラッグ&ドロップするだけでLoraを作成することができます。
「sd-webui-train-tools」のインストール方法
Stable Diffusion WebUIを起動します。
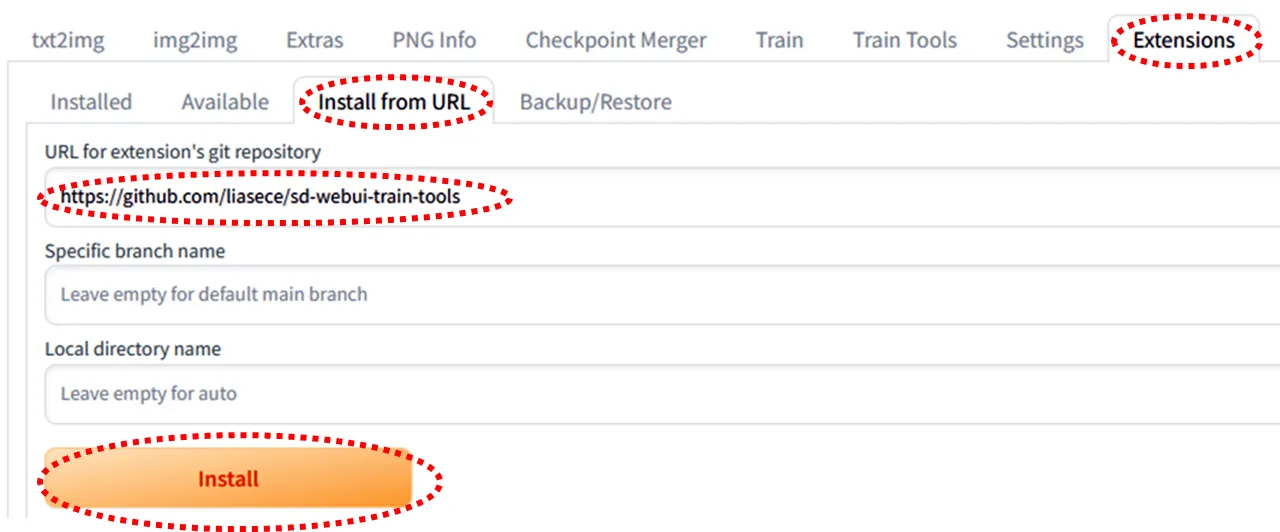
「Extensions」タブを選択し、「install from URL」タブをクリックします。
URL for extension's git repositoryに「https://github.com/liasece/sd-webui-train-tools」と入力し、Installボタンをクリックするとインストールされます。
Stable Diffusion WebUIを再起動し、「Train Tools」というタブができていれば完了です。
LoRAの作り方( sd-webui-train-tools の使い方)
「Train Tools」を選択し、「Create Project」をクリックします。
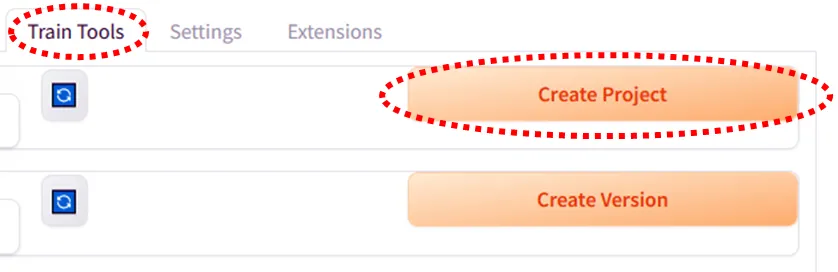
Project nameを付けます。
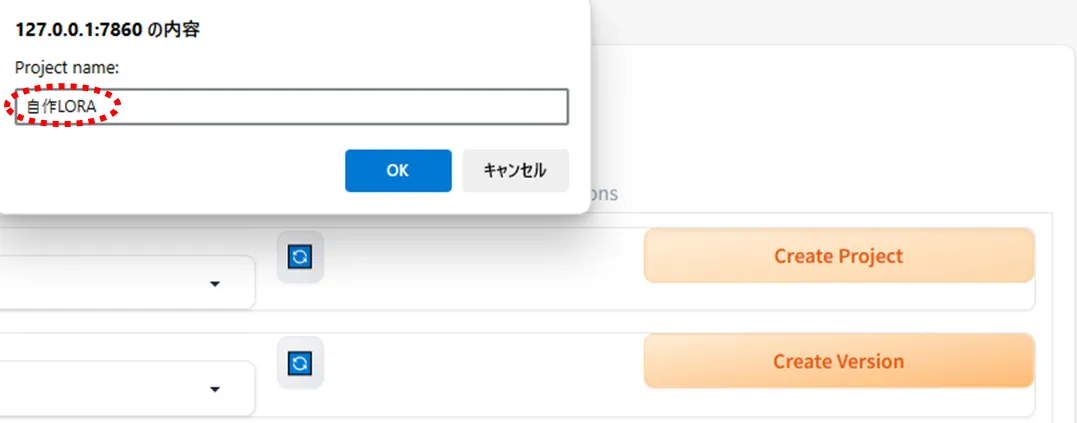
同様に「Create Version」を選択し、Version nameを付けます。
ここでは「自作LORA」としましたが、ここで日本語を入れると後々の操作がうまくいかなくなるのですべてアルファベットまたは数字にしてください。
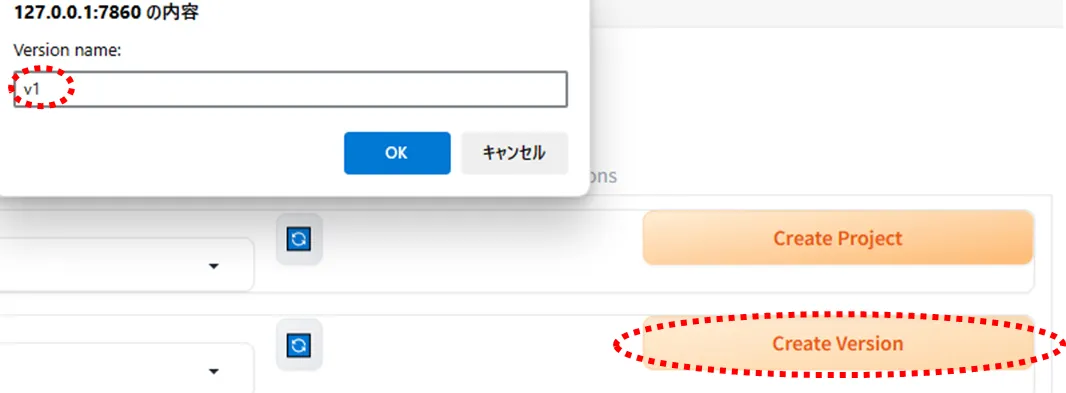
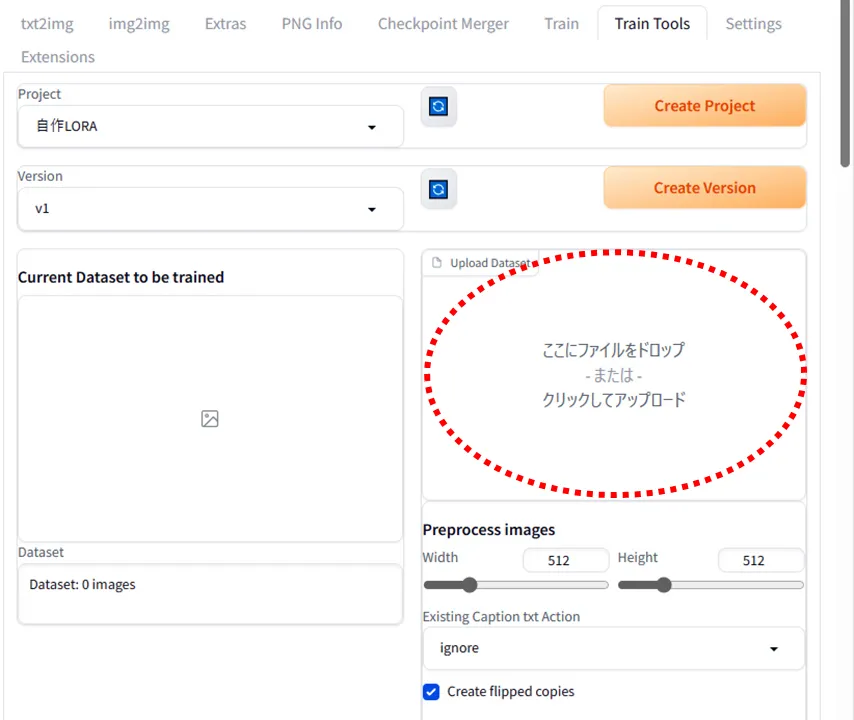
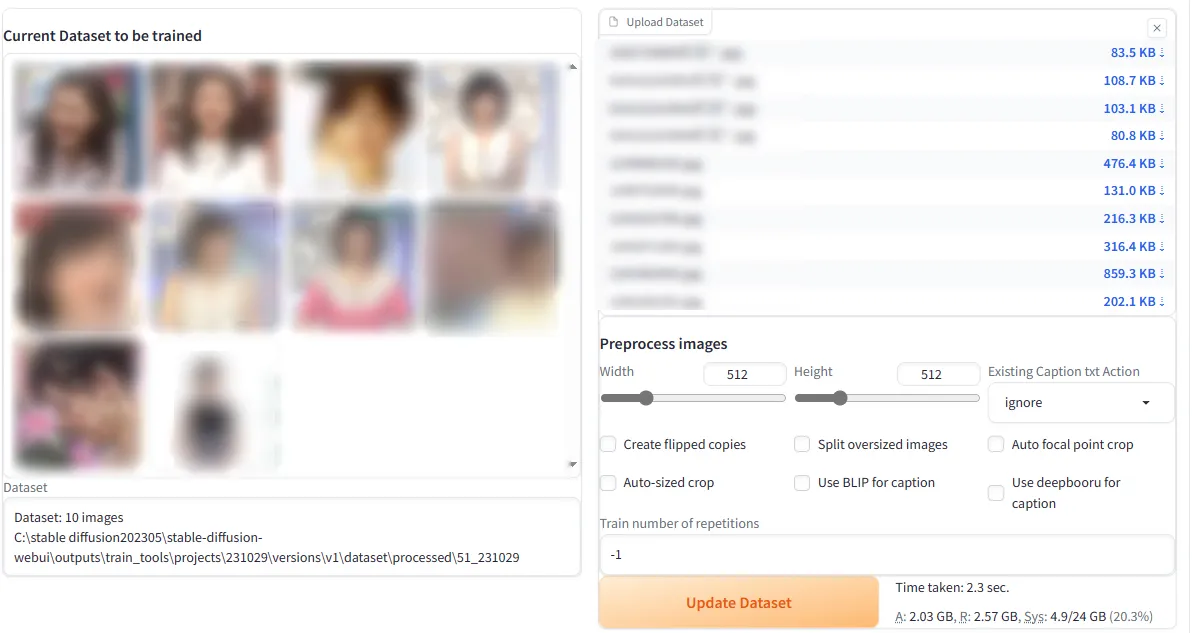
次に、学習データとして画像を10枚~20枚程度用意します。枚数が増えると学習時間も伸びます。
Upload Datasetにファイルをまとめてドロップします。
「Update Dataset」をクリック。
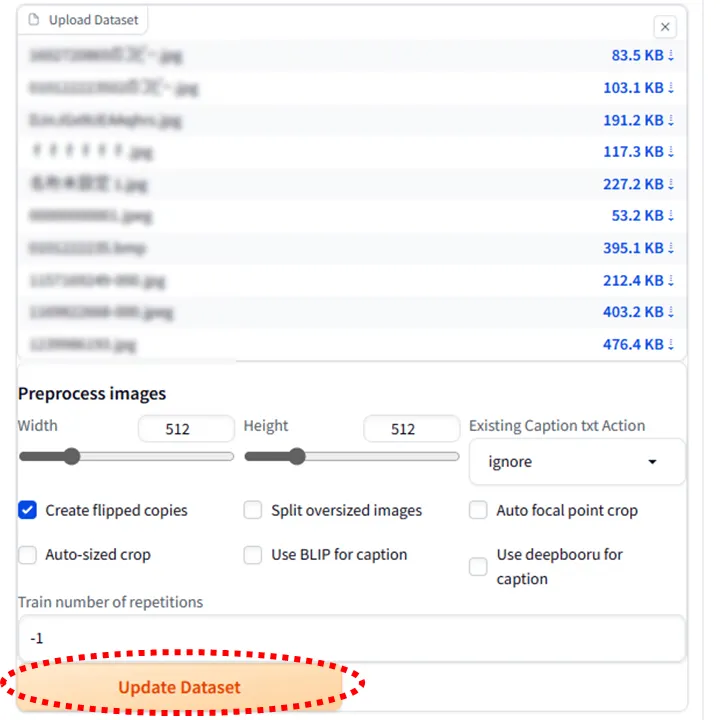
すると、左側に画像データが表示されるようになります。
続いて、LoRAファイルに作成に必要なパラメータを設定していきます。
Train base model:学習で使用するモデルcheckpoint)を選択します。学習させる画像の種類が実写系であれば、実写系のモデルを選択しましょう。
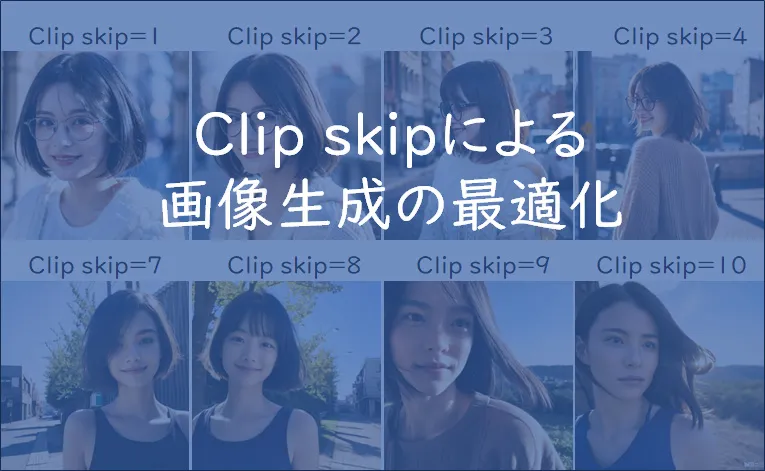
Clip skip:アニメイラスト系のモデルを使う場合は2が推奨されています。実写系のモデルを使用する場合は1と2をそれぞれ試してみて、結果が良かった方を選択してください。
Save every n epochs:何エポック毎にLoraとして保存するかを設定します。
(繰り返し回数)×(学習画像の枚数)が1エポックです。
Batch size:大きいほどLoraファイルの生成速度は上がりますが、VRAM使用量も増えます。とりあえず初期設定の1で良いと思います。
Number of epochs:学習の総エポック数を設定します。
(繰り返し回数)×(学習素材の枚数)×(エポック数)が最終的なsteps数となります。
Optimizer type:AdamWや初期設定のLionを使うのが一般的です。
Generate all checkpoint preview after train finished:特に必要が無いのでチェックを外して問題ないと思います。
「Begin Train」を押すと、Loraの学習がスタートします。学習にはかなりの時間を要します。RTX3090で36枚の画像を学習させた時には30分程度かかりました。お使いのグラフィックボードによって学習に要する時間はかなり違ってくると思います。
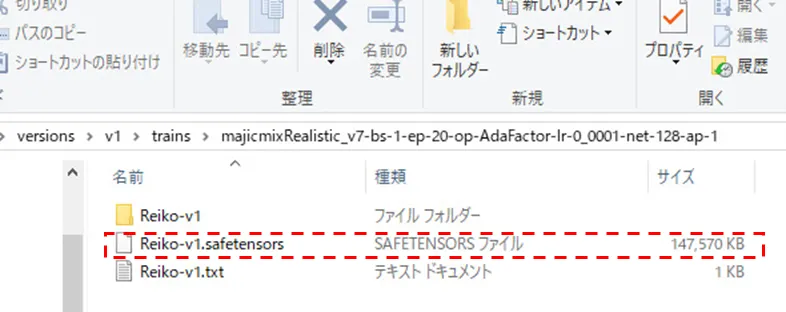
学習が終わると、「stable-diffusion-webui\outputs\train_tools\project\(設定したLora名)\versions\(設定したバージョン名)\trains」の中に、Loraファイルが保存されます。
作ったLoRaでの画像生成の方法
作成したLoRaファイルのLoraフォルダへの保存
作成したLoRaファイルは先ほどのフォルダの中にある「〇〇〇.safetensors」というファイルです。このままではLoRaによる画像生成はできないので、適切なフォルダへ保存しなおす必要があります。
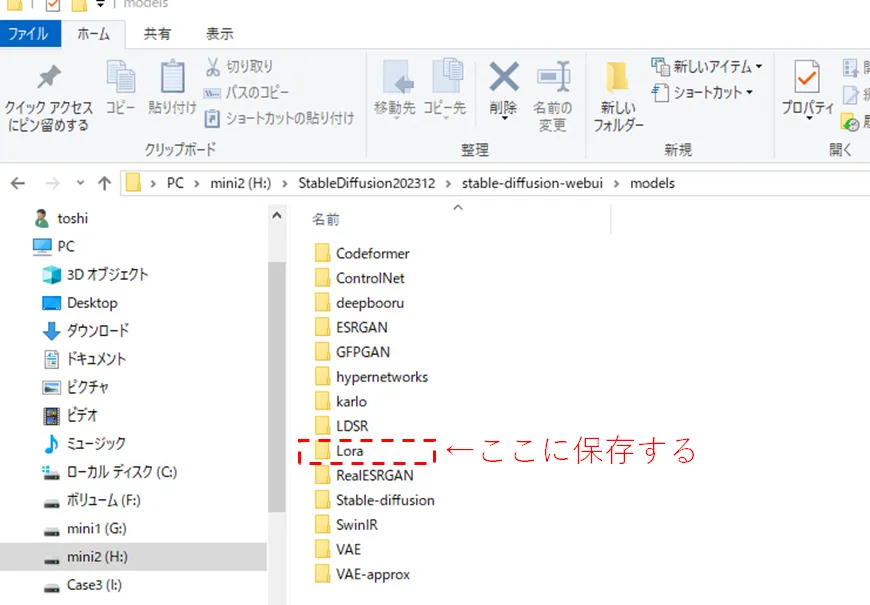
上記のLoRaファイル(「〇〇〇.safetensors」)をコピーして、「stable-diffusion-webui/models/Lora」フォルダ内にも保存します。
プロンプトにLoRaを反映させ画像を生成する
ネガティブプロンプトの下にLoraタブがあるのでここをクリックします。
次にRefreshボタンを押してください。
そうすると作成したLoRaファイル(名前は作成時のプロジェクト名)が出てくるのでクリックします。
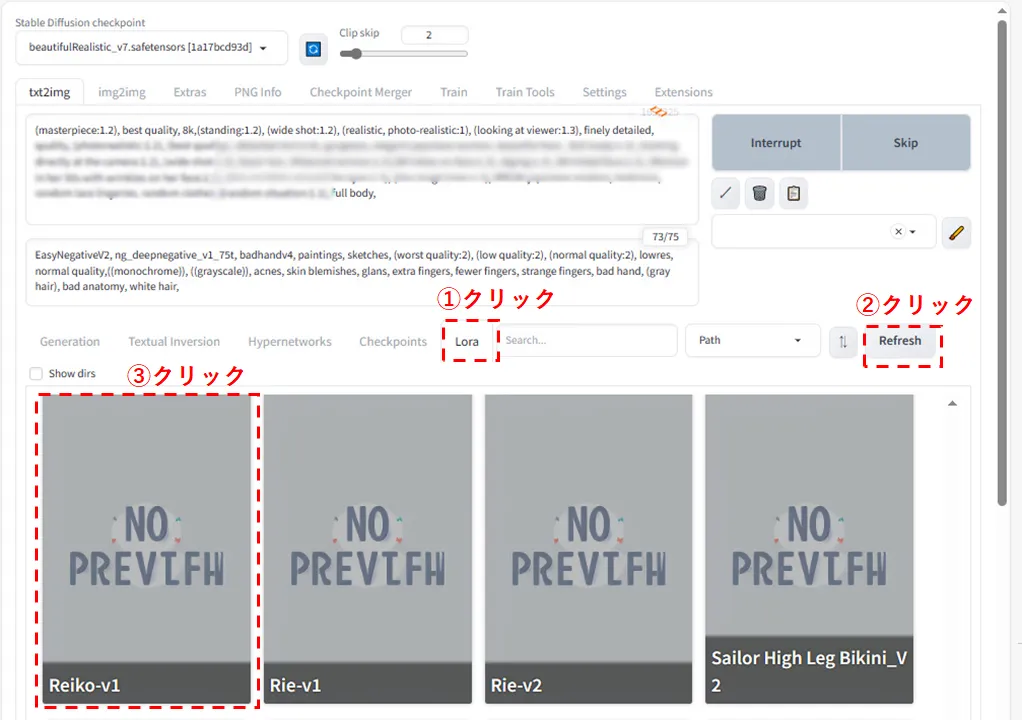
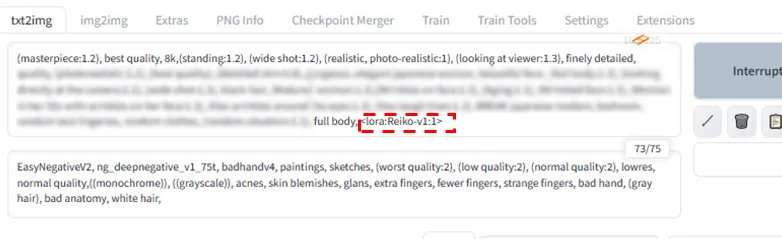
そうするとプロンプト欄に<lora:〇〇:数字>という表記が出てきます。
Generateを押すとLoRaを反映した画像が生成されます。数字を大きくするとLoRaを強く反映します。あまり大きすぎると破綻し始めます。
それぞれの条件によっても違うとは思いますが、私が作ったLoRaでは0.2~1.3くらいの範囲に最適なポイントがありました。
どのcheckpointを選択するかによっても作成したLoRaの反映のされ方は異なるのでいろいろ試してみるのが良さそうです。