

こんにちは、画像生成AIの性能を最大限に引き出すための重要な要素、LoRA学習の設定値に焦点を当てたいと思います。設定項目がいろいろありすぎて正直、最適な設定を見つけることは一筋縄ではいきません。そこで、私は25種類の異なる設定パターンを徹底的に比較し、それぞれの効果を分析し、その結果からおすすめの設定値をご紹介したいと思います。
LoRA学習の開始
まず、学習元の画像データ(実写)には30枚のpngファイルを使い、すべてのLoRA学習(25パターン)で同じデータを使っています。GPUはRTX3090を使いました。
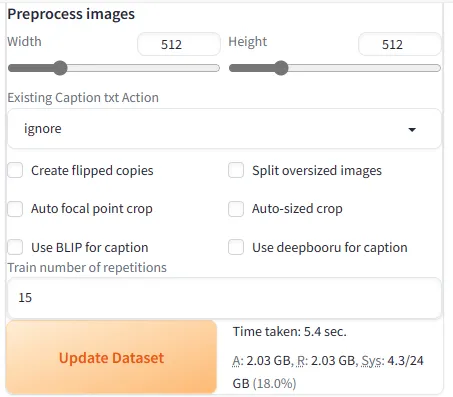
Preprocess imagesの設定値
ここでの設定値は基本的の次の写真のとおりですが、「Train number of repetitions」の値のみ、場合によっては変更しています。
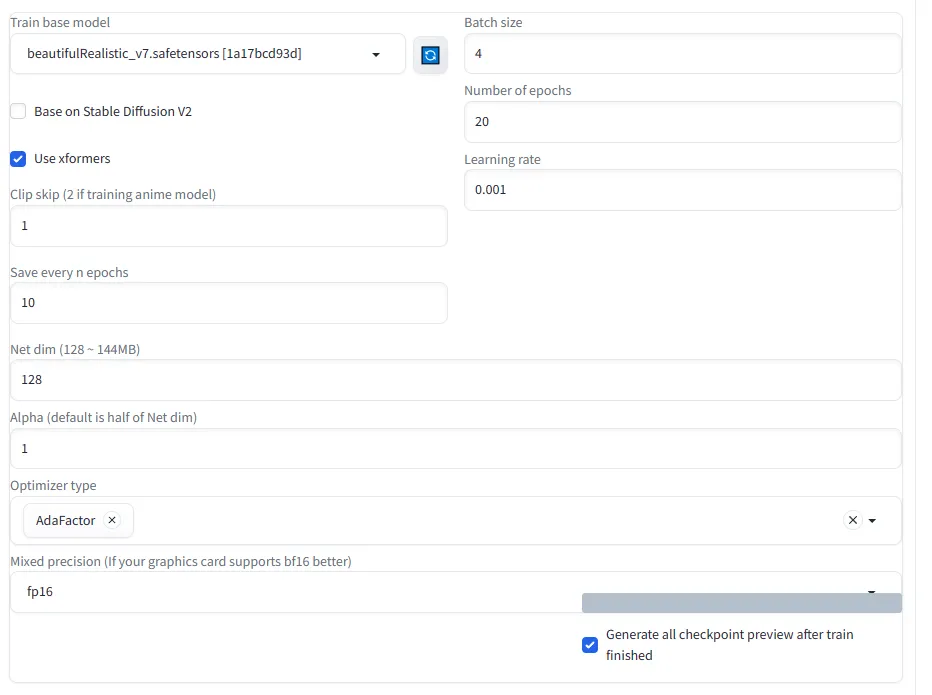
設定項目(model等)
次の設定値はすべてのパターンで同じ設定値を使いました。
・Save every n epochs=10(LoRA学習の質には関係ない)
・Net dim=128
・Mixed precision=fp16
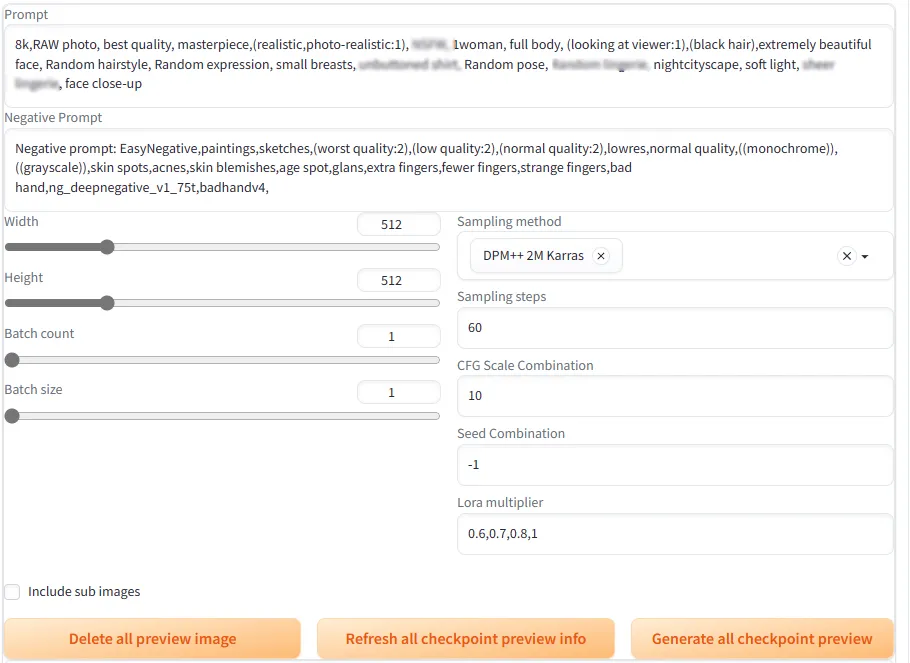
checkpoint previewの設定
ここでの設定値は次の写真のとおりで。すべてのパターンで同一の設定値になっています。
LoRA学習の出来栄えについては、checkpoint previewで生成された画像が学習元のデータの人物にどれだけ似ているかを主観的な印象点をつけて評価しています。あくまで、今回使った学習データをよく反映している設定値なので、アニメ系や学習元のデータによっても違ってくるとは思います。
全設定パターン
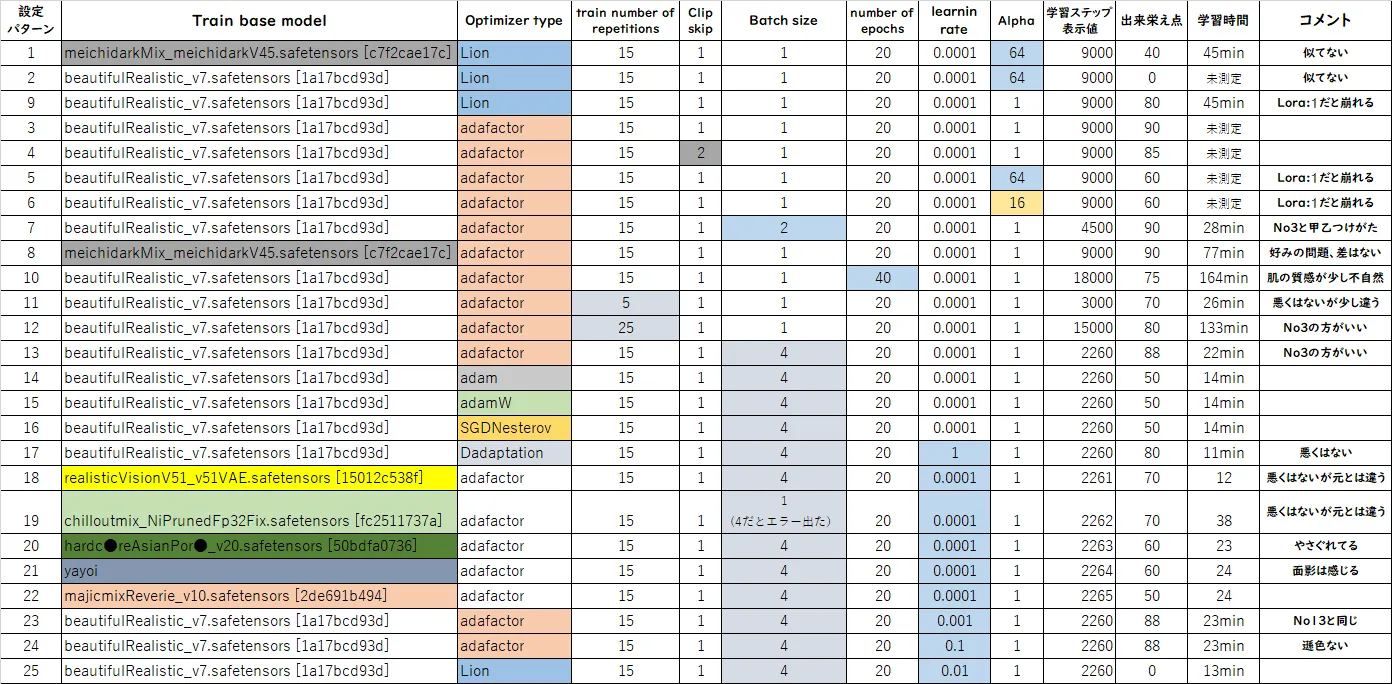
学習結果の全パターン
写真は部分的にボカシてありますのであしからず。
学習データが同じでも、できるLoRAはだいぶ異なるのがよくわかります。写真左の数字が設定パターンに対応しています。



それでは、項目毎にLoRA学習への影響についてみていきましょう。
clip skip
clip skipはアニメ系の場合は2がよくて、実写系は1がいいとよく書かれていますが、clip skip値だけ変えて比較したのが、次の設定3と4の比較です。

点数は設定パターン3の方(clip skip=1)を高く付けましたが、clip skip=2でも十分なクオリティーでした。アニメ系の学習データを使ってまた検証してみたいと思います。
number of epochs
number of epochs値だけ変えて比較したのが、次の設定3(number of epochs=20)と10(number of epochs=40)の比較です。

点数は設定3が90点、設定10が75点としました。
設定10(number of epochs=40)だと肌が少し不自然になったように感じました。また、学習時間も164minもかかりました。設定3の方は学習時間を測定し忘れてしまったのですが40~50分くらいだと思うので総ステップ数が増えたことで大分時間がかかるようになったのだと思います。
train number of repetitions
train number of repetitions値だけ変えて比較したのが、次の設定3(train number of repetitions=15)と11(train number of repetitions=5)と12(train number of repetitions=25)の比較です。

点数は設定3(train number of repetitions=15)が90点、
設定11(train number of repetitions=5)を70点、
設定12(train number of repetitions=25)を80点としました。
train number of repetitionsの値で総ステップ数が変わるので学習時間も大きく変化します。
Batch size
Batch size値だけ変えて比較したのが、次の設定3(Batch size=1)と7(Batch size=2)と13(Batch size=4)の比較です。

点数は設定3(Batch size=1)を一番高くつけましたが、ほぼ差はありませんでした。
ただ、バッチを大きくすると総ステップ数が大幅に減るので学習時間も短縮されました。それでいて、LoRAの質もあまり悪くならないのでおすすめします。ただ、modelによってはBatch sizeが1じゃないと学習できない場合もありました(設定19で使用したモデルの場合)。
optimizer type
optimizer typeの設定のみ変えて比較したのが次の写真です。
末尾に8bitという表記のあるoptimizerでも試したのですがエラーが出てしまい学習できませんでした。

設定パターン13(adafactor)を88点、設定パターン17(Ddaptaion)を80点とし、その他は50点としました。
learning rate
learning rate値のみ変えて比較したのが次の写真です。
最初に、設定13(learning rate=0.0001)、設定23(learning rate=0.001)、設定24(learning rate=0.1)としてoptimizerをadafactorにして解析していたのですが、adafactorはそもそもlearning rateを最適値を自動で調整するということを知りました。LoRAの出来栄えが同じだったのも後から納得しました。
なので、設定25ではoptimizerをLionにしてlearning rate=0.01で試しましたが、学習はすすんでいるのですが最後の画像出力が真っ黒という結果になりました。これについてはもう少し調べていきたいと思います。

Alpha
設定3(alpha=1)、設定5(alpha=64)、設定6(alpha=16)はoptimizerがadafactorです。

点数が一番良かったのは設定3(alpha=1)で90点としました。
設定5(alpha=64)、設定6(alpha=16)はともに60点としました。LoRA:1だと絵が崩れていたので悪い点にしました。
次の設定2(alpha=64)、設定9(alpha=1)はoptimizerがLionです。
この場合は、設定2(alpha=64)は点数を0点としています。というのも学習データとまったく違う人物になっているから悪い点を付けました。しかし、設定9でalpha=1にするだけで大幅な改善が見られ、点数も80点をつけました。デフォルトでalpha=64になっていますがalpha=1を激しくおすすめします。

train base model
最後にtrain base modelの違いを比較したのが次の写真です。

モデルについては学習元のデータにおおきく依存するような気もしますが、今回の学習データ(日本女性の実写)をよく反映したモデルは設定3(beautifulRealistic_v7)と設定8(meichidarkMix_meichidarkV45)がともに90点で飛びぬけて良い結果となりました。
